
Introdução
Hoje temos acesso a toneladas de informações tendo apenas uma conexão estável com a internet. Muita coisa interessante e com potencial para melhorar o seu negócio. Mas e quando a informação demanda um trabalho manual monumental para ser salva? Trabalho manual que as vezes até inviabiliza a utilização da mesma. Nem sempre temos o tempo necessário para ficar horas planilhando informações antes de utilizá-las.
Nessas situações podemos utilizar da tecnologia de Web Scraping!
 Tempo de Execução
Tempo de Execução
30 horas aproximadamente.
Investimento
R$0. Usei programação em Python e por isso foi de graça. Mas existem soluções pagas no mercado.
Nível de Dificuldade
10. Bem difícil pois exige conhecimento em programação.
Ferramentas
- Python
- BeautifulSoup
- Selenium
O que é Web Scraping?
De forma rápida e direta, Web Scraping é o ato de salvar informações da internet de maneira automatizada. O Web Scraper é como se fosse um “Robozinho” que irá executar determinados comandos configurados por você para navegar em determinadas páginas na internet e salvar as informações desejadas.
Como utilizei um algoritmo em Python para essa solução, todo o resultado pode ser customizado de acordo com a necessidade do seu negócio. Existem algumas ferramentas na internet que são pagas e vou deixar os links nesse artigo, mas já adianto que em praticamente todas existem limitações.
Por que usar do Web Scraping?
Qualquer situação onde o trabalho manual inviabiliza a execução da atividade de coleta de dados online pode ser solucionada com Web Scraping.
Imagina a seguinte situação: você precisa migrar seu e-commerce para uma nova plataforma e não tem acesso às informações de todos os seus produtos. Além disso, são 2.500 produtos cadastrados na sua base. Será que você vai animar de entrar em cada uma das páginas dos produtos e salvar todas as informações em uma planilha? Na vida, nada é impossível. Mas existem situações que a gente prefere nem tentar, não é mesmo?
A solução pode ser um Web Scraper que vai de página em página salvando em uma planilha o título dos seus produtos, url, descrição, preço, estoque ou qualquer outra informação que você quiser. Fantástico, né?
Algumas aplicações de Web Scraping para estimular sua criatividade estratégica:
Migração de informações internas
Como dito no exemplo do E-commerce, podemos vivenciar situações onde informações da nossa empresa que estão online precisam ser mudadas de servidor ou banco de dados e não temos uma forma de fazer o download das mesmas. O Web Scraper aqui salva nossa pele economizando tempo e evitando que um monte de informações valiosas se percam.
Definindo preço do seu produto
Tem dúvida de qual é o preço médio do seu produto comercializado na sua região? E se a gente colocar nosso Web Scraper para acessar lojas online e mapear para você os preços de vários produtos e serviços diferentes? Ai sim, ein!
Ao final você terá uma planilha ótima para definir um preço competitivo dos seus produtos ou até mesmo bolar promoções específicas.
Web Scraping na sua estratégia de Marketing Digital
Todo mundo quer um lugarzinho nas primeiras pesquisas do Google. Que tal colocar seu Web Scraper para mapear todas as postagens que seu concorrente tem feito e identificar quais são as principais palavras-chave que ele trabalha?
Ou você pode pegar trend topics em sites como LinkedIn, Medium ou Reddit e mandar nosso robozinho identificar oportunidades de criação de conteúdo. São muitas as oportunidades para bombar seu marketing digital.
Espionando as fraquezas do seu concorrente
Trabalhar em cima das fraquezas do seu concorrente também é possível com Web Scraping. Podemos estruturar em uma planilha a análise das principais reclamações que nossos concorrentes recebem no Reclame Aqui. Estratégia excelente para que você foque naquilo que realmente incomoda seu público-alvo.
Identificando novos mercado com Web Scraping
Existem toneladas de dados públicos oferecidos pelos canais oficiais do governo. Informações como quantidade e segmento de CNPJ’s abertos e fechados. Estabelecimentos com seus endereços. Informações gerais do mercado. Todas essas informações podem ser reunidas com nosso Web Scraper, possibilitando que você identifique oportunidades não exploradas por outras empresas.
Outra abordagem seria procurar base de dados em empresas privadas. O Twitter mesmo disponibiliza acesso aos tweets da rede. Ou você pode colocar seu Web Scraper para mapear comentários em fóruns diversos e identificar tendências do seu mercado.
Encontrando possíveis licitações
Outra oportunidade de venda que você pode explorar são as licitações governamentais. Esse inclusive é o exemplo que fiz usando Web Scraping. No decorrer do artigo você pode conferir o algoritmo que busca no site do governo federal licitações de acordo com um período de tempo. No meu exemplo, puxei uma base com mais de 20.000 licitações!
Web Scraping na prática
- Python
- BeautifulSoup
- Selenium
O conceito do Web Scraping é relativamente simples. Não significa que a execução seja hahaha. Mas o lance é o seguinte: o Web Scraper irá se orientar de acordo com o HTML/CSS da página que estamos navegando. Por isso, entender desses conceitos é primordial para criar um Web Scraper.
Quando temos páginas interativas e que utilizam de linguagens como Java Script, torna necessário simularmos como se fosse um humano clicando em elementos para conseguirmos acessar determinados conteúdos.
O Selenium é uma tecnologia muito utilizada por equipes de testes. Ele faz exatamente isso. Simula uma interação como se fosse um humano fazendo. Isso é muito útil para os testers identificarem erros de forma automatizada. E também é útil na nossa solução, pois queremos nosso Web Scraper clicando e navegando nas páginas para acessar conteúdos.
Por fim, usei uma biblioteca do Python chamada BeautifulSoup para manipular as informações encontradas no formato de HTML/CSS.
Clique aqui para acessar meu Web Scraper no GitHub.
Web Scraping: Passo 1
Abaixo você pode conferir as bibliotecas importadas:
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Web Scraping: Passo 2
Primeira coisa a ser feita é criar as variáveis que receberão nossas informações. Nesse caso separei em título e conteúdo devido a forma que era exibido no website.
title_licitation = []
content_licitation = []
Web Scraping: Passo 3
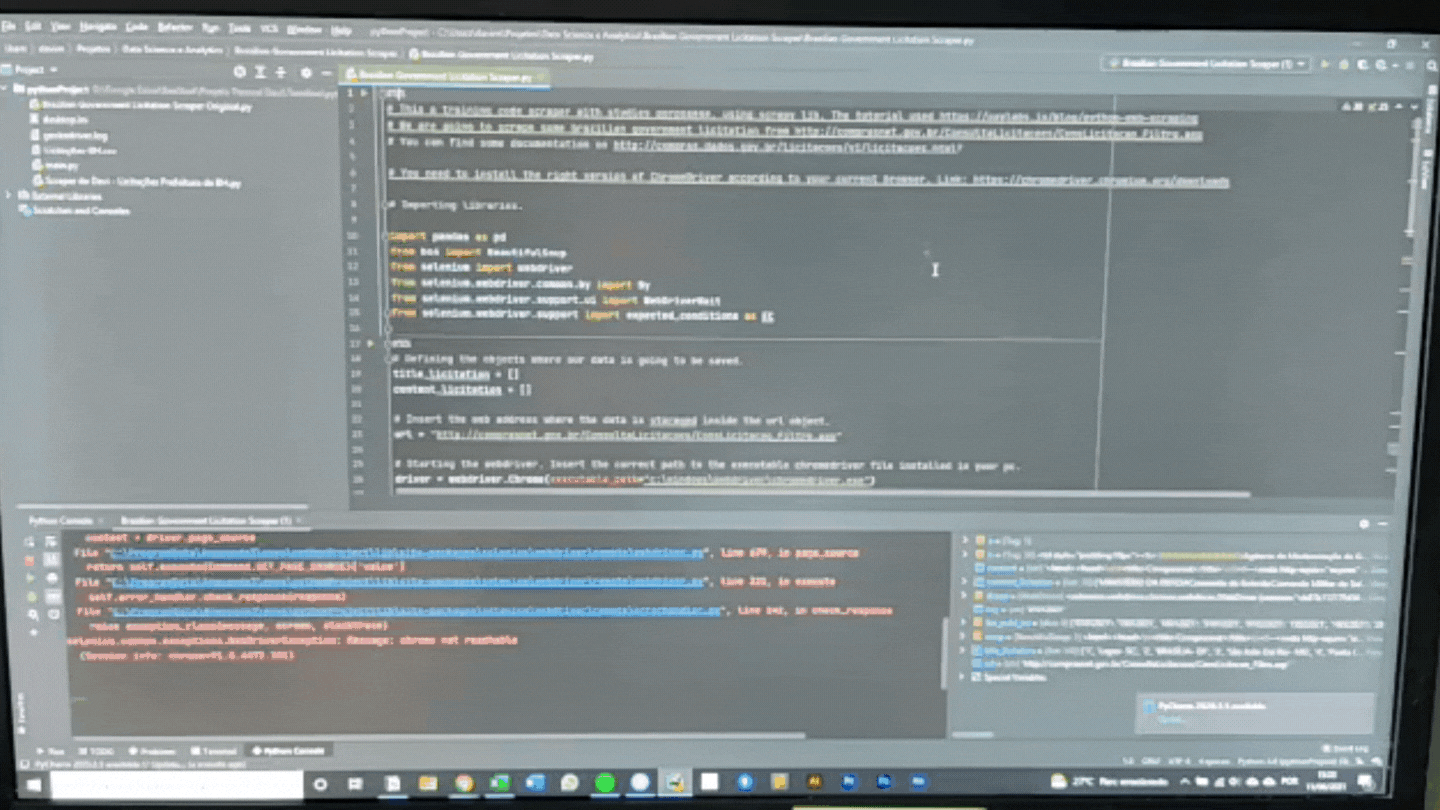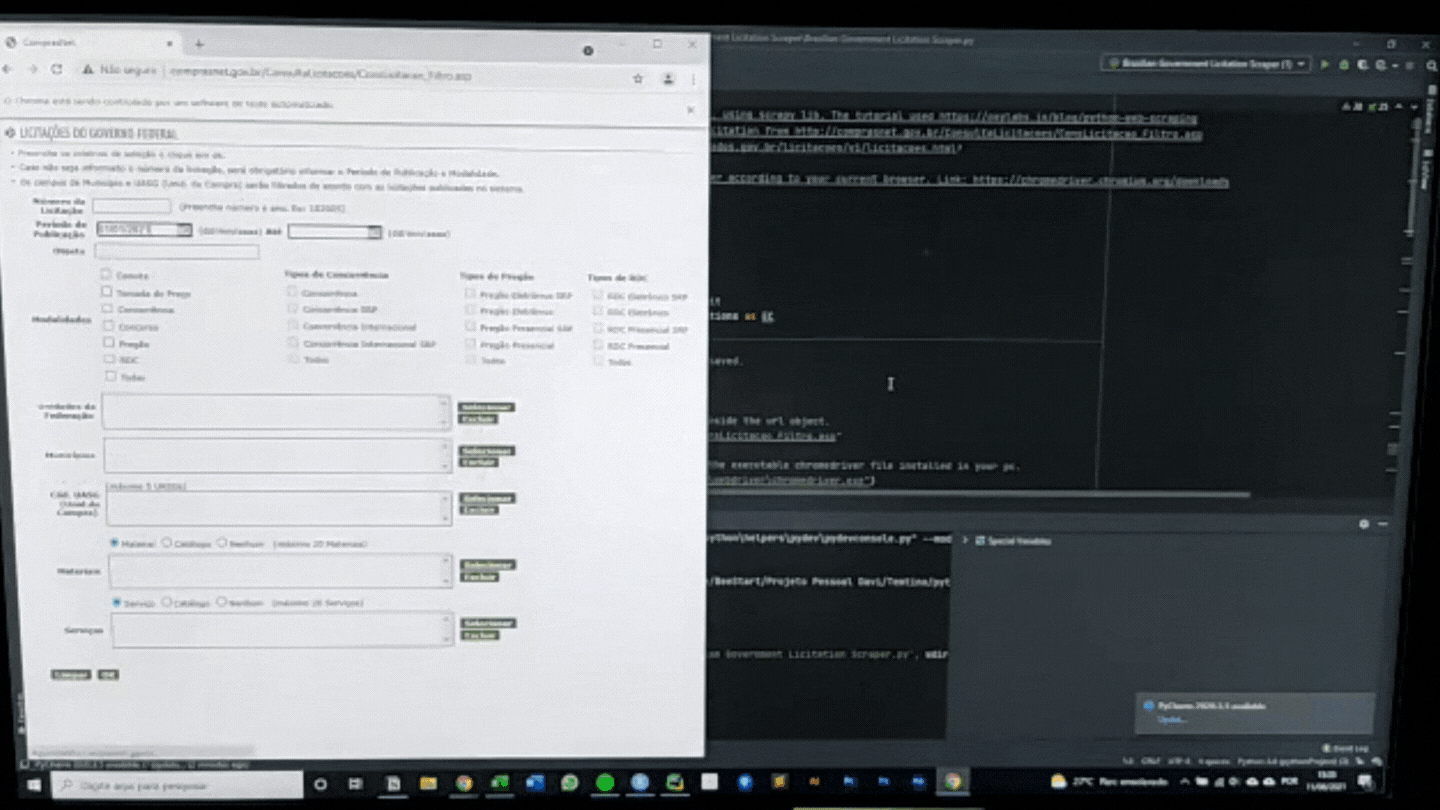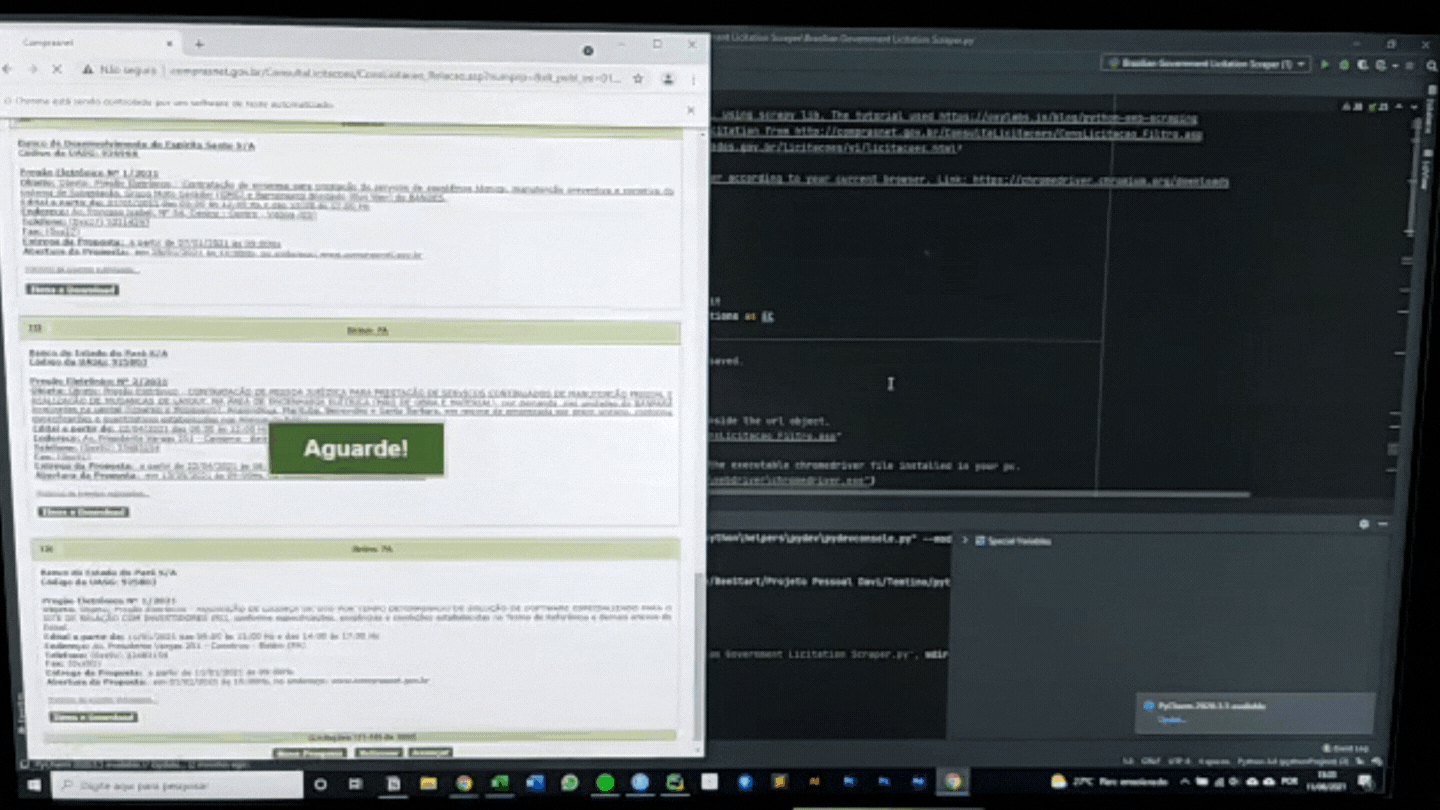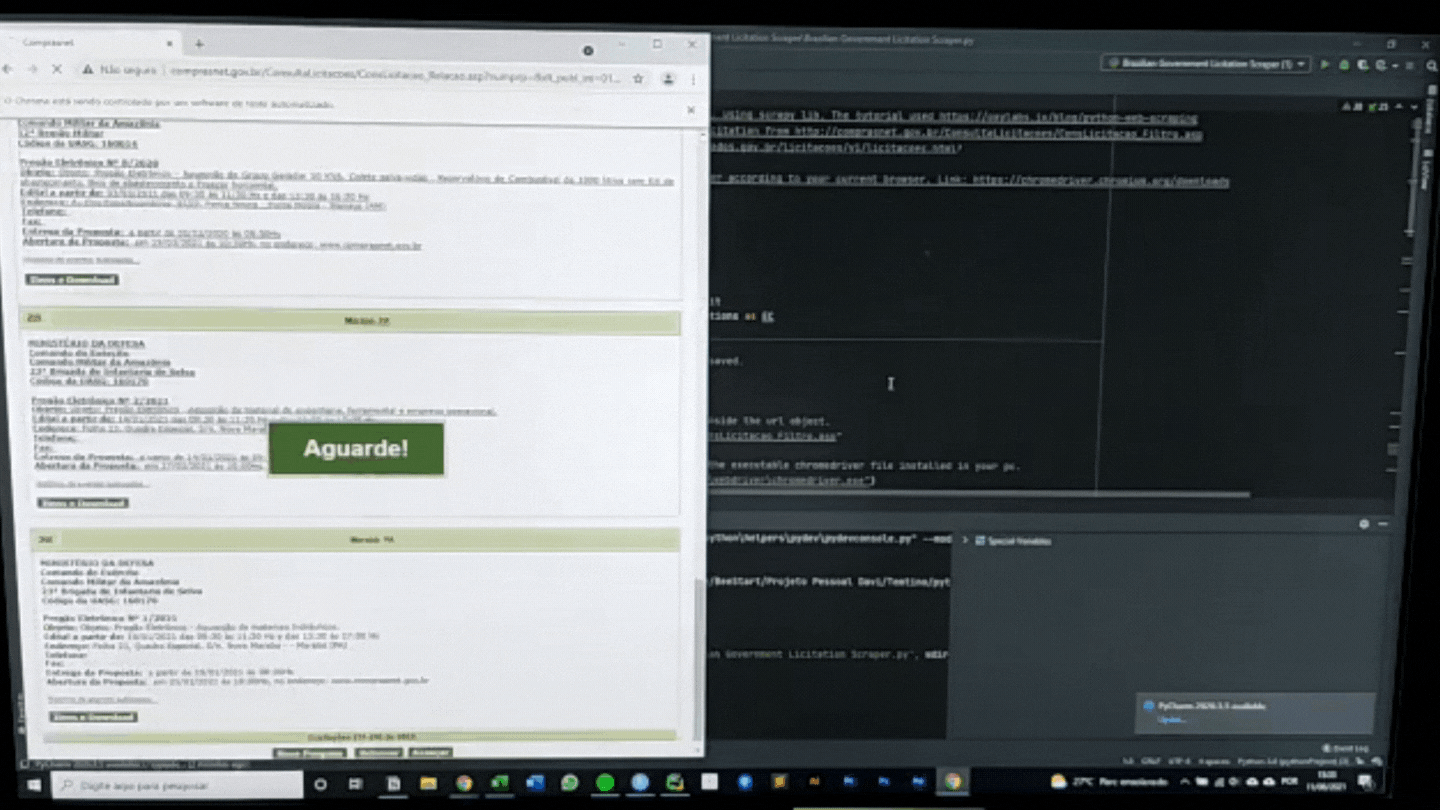
Defini a url da página onde queremos puxar os dados dentro da variável “url”. A variável “driver” está iniciando nosso Web Driver instalado em nosso computador. Por fim, o Web Driver recebe a url e é direcionado ao site.
url = "http://comprasnet.gov.br/ConsultaLicitacoes/ConsLicitacao_Filtro.asp"
driver = webdriver.Chrome(executable_path="c:\windows\webdriver\chromedriver.exe")
driver.get(url)
Web Scraping: Passo 4
Como nada na vida vem perfeitamente da forma que desejamos, o website do governo somente permite pesquisa com um intervalo de 15 dias. Por isso, precisei criar um dictionarie contendo os pares de datas, sendo na ordem de data inicial e data final. Caso você queira utilizar do código com datas diferentes, basta alterar nessa variável.
list_publ_ini = {"01012021":"15012021","16012021":"31012021","01022021":"15022021","16022021":"28022021","01032021":"15032021","16032021":"31032021","01042021":"15042021","16042021":"30042021"}
Web Scraping: Passo 5
Agora a coisa começa a ficar um pouco complicada. Utilizei dois for loops, dentro de um while que por sua vez está dentro de outro for loop. Deu um nó ai na cabeça, né? Eu sei bem como é. Vou tentar explicar bem detalhadamente.
for key in list_publ_ini:
WebDriverWait(driver, 1).until(EC.element_to_be_clickable((By.XPATH, "//input[@name='Limpar']"))).click()
driver.find_element_by_xpath("//input[@name='dt_publ_ini']").send_keys(key)
driver.find_element_by_xpath("//input[@name='dt_publ_fim']").send_keys(list_publ_ini[key])
driver.find_element_by_xpath("//input[@name='chkTodos']").click()
driver.find_element_by_xpath("//input[@name='ok']").click()
while True:
content = driver.page_source
soup = BeautifulSoup(content, features="lxml")
for a in soup.findAll(attrs={'class':'td_titulo_campo', 'align':'center'}):
title_licitation.append(a.text.strip())
for b in soup.findAll(attrs={'style':'padding:10px'}):
content_licitation.append(b.text.strip())
try:
WebDriverWait(driver, 1).until(EC.element_to_be_clickable((By.XPATH,"//input[@name='btn_proximo']"))).click()
except:
WebDriverWait(driver, 1).until(EC.element_to_be_clickable((By.XPATH,"//input[@name='Pesquisa']"))).click()
break
driver.quit()
O primeiro for loop contém as instruções ao nosso Web Driver com as seguintes ordens de comando:
- O WebDriver busca o botão limpar para garantir que o formulário de pesquisa esteja limpo antes de inserir as informações.
- Insere a data inicial da nossa pesquisa de acordo com a variável list_publ_ini que criamos.
- Insere a data final da nossa pesquisa de acordo com a variável list_publ_ini que criamos.
- Clica no botão “Todos” para selecionar todas as modalidades.
- Clica no botão “Ok” para fazer a pesquisa.
A função while é utilizada para navegar em todas as páginas resultantes da nossa pesquisa enquanto ela encontrar algum conteúdo. Dentro do while, temos dois for loops:
- Primeiro for encontra o título das licitações via ‘class’:’td_titulo_campo’ e salva as informações dentro de title_licitation.
- O segundo for encontra o conteúdo das licitações via ‘style’:’padding:10px’ e salva as informações dentro de content_licitation.
Ao final, através do parâmetro try, nosso algoritmo procura o botão “Próximo” e, caso positivo, refaz essa rotina. Em caso negativo, ele recebe os comandos para voltar ao campo de nova pesquisa pelo parâmetro except.
Voltando à página de pesquisa, nosso Web Scraper vai para o próximo conjunto de datas e continua essa rotina até esgotar a lista list_publ_ini.
Gostou? Então clica ali naquela estrelinha ![]() no seu navegador e salva esse conteúdo nos seus favoritos assim fica mais fácil para você consultá-lo sempre que precisar!
no seu navegador e salva esse conteúdo nos seus favoritos assim fica mais fácil para você consultá-lo sempre que precisar!
Tem a sensação que todas suas decisões estão sendo erradas? Você pode estar sofrendo da fadiga de decisão!
Obrigado pela agradável companhia e deixe nos comentários qualquer dúvida ou sugestão ![]()
Abraaaaaço.
Deixe um Comentário